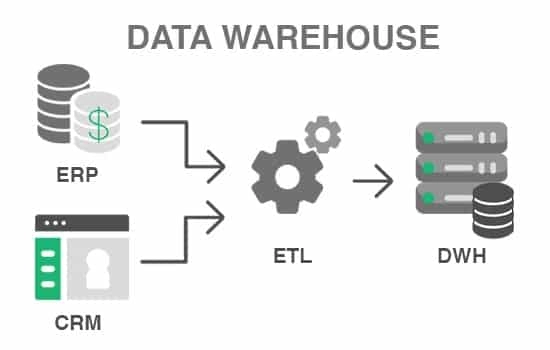
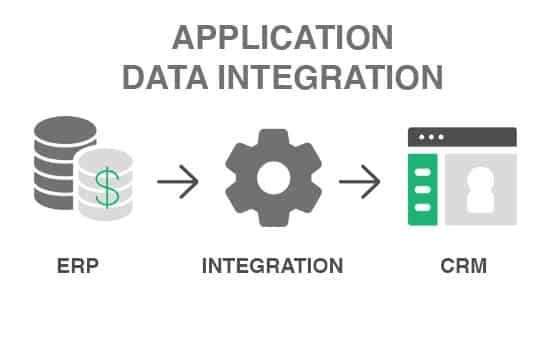
- Products

DataOps Suite
Intelligent Data Validation and Analytics Testing Platform with Agentic AI.

ETL Validator
Automated Data Validation and ETL Testing with Agentic AI.

BI Validator
Smarter BI Validation For Power BI, Tableau, Oracle Analytics – Accelerated by AI Agents.

Data Quality Monitor
Proactive Data Quality with Agentic AI – Predict, Prevent, Govern.

Test Data Manager
Generate compliant and realistic test data for all your testing needs, enabled by Agentic AI.
- Resources



- Products
DataOps Suite
Intelligent Data Validation and Analytics Testing Platform with Agentic AI.
ETL Validator
Automated Data Validation and ETL Testing with Agentic AI.
BI Validator
Smarter BI Validation For Power BI, Tableau, Oracle Analytics – Accelerated by AI Agents.
Data Quality Monitor
Proactive Data Quality with Agentic AI – Predict, Prevent, Govern.
Test Data Manager
Generate compliant and realistic test data for all your testing needs, enabled by Agentic AI.
- Resources